
Introduction
This project is for translating English sentence to French sentence. I built a deep neural network(bidirectional RNN with GRU units) as part of end-to-end machine translation pipeline. The completed pipeline will accept English text as input and return the French translation. I compared the results of various RNN structures at the end.
Process
- Preprocess - Convert text to sequence of integers
- Models - Created bidirectional RNN with GRU units which accepts a sequence of integers as input and returns a probability distribution over possible translations
- Prediction - Run the model on English text.
Environment
- AWS EC2 p2.xlarge
- Jupyter Notebook
- Python 3.5, Keras, TensorFlow 1.1
Preprocessing dataset
The most common datasets used for machine translation are from WMT. However, that will take a long time to train a neural network on. So, I used comparably the small dataset for my project’s purpose.
Load Data
English and French Data are loaded. The both datasets are sequenced already.
import helper
# Load English data
english_sentences = helper.load_data('data/small_vocab_en')
# Load French data
french_sentences = helper.load_data('data/small_vocab_fr')
The sample of pair English and French sentence are below.
small_vocab_en Line 1: new jersey is sometimes quiet during autumn , and it is snowy in april . small_vocab_fr Line 1: new jersey est parfois calme pendant l’ automne , et il est neigeux en avril .
small_vocab_en Line 2: the united states is usually chilly during july , and it is usually freezing in november . small_vocab_fr Line 2: les états-unis est généralement froid en juillet , et il gèle habituellement en novembre .
Tokenize and Padding
Tokenize the words into ids.
import project_tests as tests
from keras.preprocessing.text import Tokenizer
def tokenize(x):
"""
Tokenize x
:param x: List of sentences/strings to be tokenized
:return: Tuple of (tokenized x data, tokenizer used to tokenize x)
"""
# TODO: Implement
tokenizer = Tokenizer()
tokenizer.fit_on_texts(x)
return tokenizer.texts_to_sequences(x), tokenizer
Add padding to make all the sequences the same length.
import numpy as np
from keras.preprocessing.sequence import pad_sequences
def pad(x, length=None):
"""
Pad x
:param x: List of sequences.
:param length: Length to pad the sequence to. If None, use length of longest sequence in x.
:return: Padded numpy array of sequences
"""
# TODO: Implement
return pad_sequences(x, maxlen=length, padding='post', truncating='post')
The below is the results by Tokenizing and Padding.
The quick brown fox jumps over the lazy dog .
[1 2 4 5 6 7 1 8 9] - Tokenizing
[1 2 4 5 6 7 1 8 9 0] - Padding
Model
I tested several models to get better accuracy in test dataset. I will present the best model which is bidirectional RNN with GRU and Embedding Layer. RNN with GRU or LSTM is a good neural network model for sequence data like sentence or stock price. Also Embedding layer is one of important concept for Natural Language Processing. At the end, I will compare the results of different models.
Embedding Layer
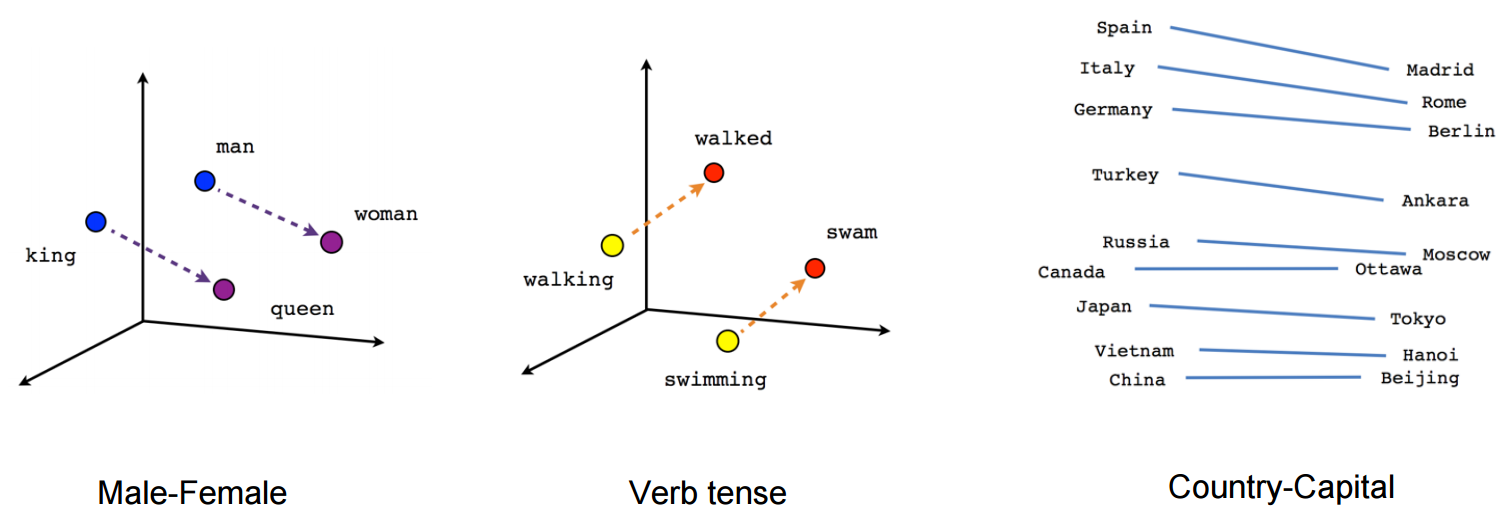
Image from TensorFlow
Word2Vector concept (used in Embedding Layer) is very important in Natural Language Processing. Each word itself which is converted in the number here doesn’t have any meaning for machine. So we need to convert the word to the meaningful thing for machine. The word can be converted to the vector using n-gram. The vector presents relations among words. You can check Embedding Projector of Google visually what it means.
Bidirectional RNN
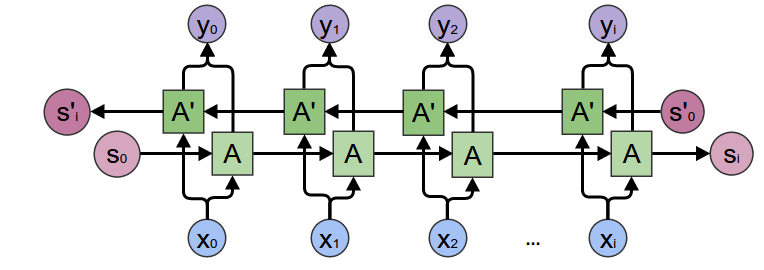
Image from colah’s blog
Bidirectional RNN is basically two RNNs which have normal RNN and reversed RNN. It improves the test accuracy technically by training RNN using reverse sequenced dataset. You can find the nice explanation from Understanding Bidirectional RNN in PyTorch by CeShine Lee
Final Structure
| Layer (type) | Output Shape | Param # |
|---|---|---|
| input_3 (InputLayer) | (None, 21) | 0 |
| embedding_3 (Embedding) | (None, 21, 345) | 69000 |
| bidirectional_5 (Bidirectional) | (None, 512) | 924672 |
| repeat_vector_3 (RepeatVector) | (None, 21, 512) | 0 |
| bidirectional_6 (Bidirectional) | (None, 21, 256) | 492288 |
| time_distributed_3 (TimeDististibuted) | (None, 21, 345) | 88665 |
Total params: 1,574,625
Trainable params: 1,574,625
Non-trainable params: 0
from keras.layers import GRU, Input, Dense, TimeDistributed, Bidirectional, RepeatVector
from keras.models import Model, Sequential
from keras.layers import Activation
from keras.optimizers import Adam
from keras.losses import sparse_categorical_crossentropy
from keras.layers.embeddings import Embedding
def model_final(input_shape, output_sequence_length, english_vocab_size, french_vocab_size):
"""
Build and train a model that incorporates embedding, encoder-decoder, and bidirectional RNN on x and y
:param input_shape: Tuple of input shape
:param output_sequence_length: Length of output sequence
:param english_vocab_size: Number of unique English words in the dataset
:param french_vocab_size: Number of unique French words in the dataset
:return: Keras model built, but not trained
"""
inputs = Input(shape=input_shape[1:])
embed = Embedding(input_dim=english_vocab_size, output_dim=french_vocab_size)(inputs)
biGru_1 = Bidirectional(GRU(units=256, dropout=0.25, recurrent_dropout=0.25))(embed)
repeatVec = RepeatVector(output_sequence_length)(biGru_1)
biGru_2 = Bidirectional(GRU(units=128, return_sequences=True, dropout=0.25, recurrent_dropout=0.25))(repeatVec)
outputs = TimeDistributed(Dense(units=french_vocab_size, activation='softmax'))(biGru_2)
model = Model(inputs=inputs, outputs=outputs)
############################################################################################
# Compile
############################################################################################
learning_rate=0.001
model.compile(loss=sparse_categorical_crossentropy,
optimizer=Adam(learning_rate),
metrics=['accuracy'])
return model
Prediction
Above model’s accuracy of validation dataset reached 97.77%.
The example of prediction:
English: He saw an old yellow truck
French: Il a vu un vieux camion jaune
Prediction: il a vu un vieux camion jaune <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD>
Comparison
The condition of training for all model:
10 epochs, learning rate = 0.001
| Structure | Embedding | Dropout | Maximum Accuracy |
|---|---|---|---|
| RNN: GRU 100 units | X | X | 65.10% |
| RNN: GRU 256 units | X | X | 68.30% |
| RNN: GRU 100 units | O | X | 84.01% |
| RNN: GRU 256 units | O | X | 92.06% |
| Bidirectional RNN: GRU 256, 128 units | O | X | 83.65% |
| Bidirectional RNN: GRU 256, 128 units | O | 40% | 82.17% |
| Bidirectional RNN: GRU 256, 128 units | O | 25% | 86.54% |
The best normal RNN is reached over 90% accuracy in 10 epochs. However it didn’t improve much accuracy after over 10 epochs because its structure is not complex enough to catch the complexity of data. It reaches pretty good accuracy faster, but it can’t achieve very high accuracy because of comparably simpler structure than bidirectional RNN.
On the other hand, the best bidirectional RNN is reached to 86% in 10 epochs, but it is eventually reached over 97% accuracy after 40 epochs.
Source Code
Reference
[1] Artificial Intelligence. (n.d.). Retrieved from https://www.udacity.com/course/ai-artificial-intelligence-nanodegree–nd898